
The frontier AI race never slows down. Just a month after xAI’s Grok-4 launch, OpenAI unveiled GPT-5 on August 7th, pushing the competitive bar higher yet again.
While the online buzz around GPT-5 has been mixed—some early video reviewers called it “less revolutionary”—my own testing and research paint a different picture. GPT-5 is a significant leap forward, not just an incremental update. Its combination of higher accuracy (lower hallucination rates), cheaper token pricing, massive context windows, and multimodal capabilities has the potential to usher in a new era for AI application development.
But GROK4 topped Andon Labs’ Vending-Bench, outperforming GPT-5 by 31%, earning $1,115.25 more in the benchmark simulation. That shows its unique strength in practical, long horizon tasks.
Before we decide who is the winner, let’s break down the key new features and see how GPT-5 stacks up against Grok-4 across benchmarks and real-world use cases.
Feature Highlights of GPT-5
OpenAI describes GPT-5 as a unified, smarter, and more broadly useful system—and much of that marketing talk holds up in practice. Here’s what stands out:
1. Unified Model with Broad Strengths
GPT-5 isn’t just an upgrade in one area—it’s been tuned to excel in writing, coding, and health-related tasks, three major ChatGPT use cases. The improvements aren’t flashy gimmicks but targeted upgrades that matter for professional and enterprise users. GPT-5 puts a model router in front of the underlying models in GPT-5-main and GPT-5-thinking categories, so the users don’t have to pick which models to use.
2. Faster, More Efficient Reasoning
The model responds more quickly, handles long and complex prompts better, and produces more accurate, safer answers across a wider range of queries.
OpenAI stated GPT‑5 (with thinking) performs better than OpenAI o3 with 50-80% less output tokens across capabilities, including visual reasoning, agentic coding, and graduate-level scientific problem solving.
3. Accuracy Improvements
GPT-5 trained targeting two parts of hallucinations. One was on parts for browse on. One was for browse off. Browse on training was for training the model to browse effectively, this call out to the internet, when up-to-date sources are useful. Browse off training was to reduce factual errors when the model needs to rely on its own internal knowledge. The model uses LLM grader to validate the training. The hallucinations in both parts are improved.
OpenAI claims GPT-5 is:
- ~45% less likely to hallucinate than GPT-4o
- ~80% less likely to hallucinate than OpenAI’s o3 model (even with web search enabled)
- On fact-seeking benchmarks like LongFact and FActScore, GPT-5 thinking produces 6× fewer hallucinations than o3
Not everyone agrees—my friend at AIMon found reduced accuracy compared to GPT-4.5 in their SimpleQA tests. We suspect it was due to model routing errors, some of the previously straightforward questions are not answered directly now. But on aggregate, GPT-5 appears more reliable on open-ended and real-world knowledge queries.
4. Less Sycophantic, More Honest and Professional Responses
GPT-4 was often criticized for its sycophancy—a tendency to mirror the user’s stated view, even when it was wrong. This behavior stemmed largely from its preference training: reinforcement learning from human feedback (RLHF) rewarded answers that people liked, which often meant being agreeable and confident rather than accurate. The result was a model that sometimes misled by agreeing too readily. The new model, by contrast, is trained on production style conversations and it directly penalizes sycophantic completions. As a result, GPT-5 learns to disagree when the user is wrong, and learns to separate tone politeness from factual agreement. It is a less sycophantic model.
GPT-5 reduces over-agreement and “yes-man” behavior:
- Sycophancy dropped from 14.5% to <6%
- Responses are less emoji-heavy and feel more like talking to a PhD-level colleague than a friendly assistant.
- Over-agreement rates fell without hurting user satisfaction.
This honesty translates to better trust and transparency—crucial for enterprise AI adoption:
- On the CharXiv benchmark (with missing images), GPT-5’s deception rate was just 9% versus 86.7% for o3.
- In real ChatGPT traffic, deception dropped from 4.8% (o3) to 2.1% (GPT-5 reasoning).
5. Safer and More Helpful in Sensitive Domains
A new safe completions training approach means GPT-5 can answer nuanced questions in dual-use domains like virology, where older models might default to rigid refusals. Instead of deciding only to comply or refuse, the model is trained to maximize helpfulness subject to a safety constraint on the response itself. Now there are three paths to answer a question: direct answer, a safe completion where the model stays high level and non-operational without including risky details, and a refusal but with some level of redirection to allow constructive alternatives.
6. Biological Risk Safeguards
OpenAI treats GPT-5 thinking as high capability in biological and chemical domains. It underwent 5,000+ hours of red-teaming, multi-layered safeguards, and thorough risk modeling—while showing no evidence of enabling severe harm.
7. GPT-5 Pro for Advanced Reasoning
Replacing OpenAI’s o3-pro, GPT-5 Pro adds extended reasoning and parallel compute:
- 88.4% on GPQA (state-of-the-art)
- Outperforms standard GPT-5 reasoning in 67.8% of complex prompts
- 22% fewer major errors on real-world reasoning tasks
Benchmark Comparison: GPT-5 vs. Grok-4
Benchmark results vary by methodology.
| Benchmark | GPT-5 | Grok-4 |
| AIME 2025 (Math) | 94.6% | 98.4% |
| GPQA (Science, with GPT-5 Pro) | 88.4% | 87.5% |
| Humanity’s Last Exam | 42% | 40% |
| Andon Vending-Bench | $3578.90 | $4694.15 |
| SWE Bench | 74.9 | 75 |
GPT-5 leads in science and the more holistic Humanity’s Last Exam (HLE). Grok-4 holds a math edge, slight lead in SWE Bench and a huge lead in the Andon Vending-Bench.

Among those benchmarks, I’d emphasize the Humanity’s Last Exam and Andon Vending-Bench. Let’s take a look.
The Humanity’s Last Exam (HLE) Factor
AI capability is evaluated based on benchmarks, yet as their progress accelerates, benchmarks become quickly saturated, losing their utility as a measurement tool. Performing well on formerly frontier benchmarks such as MMLU and GPQA are no longer strong signals of progress as frontier models reach or exceed human level performance on them.
The HLE, created by Scale AI and the Center for AI Safety, is designed to combat benchmark saturation. Traditional tests like MMLU and GPQA are becoming less useful as models hit or exceed human-level scores.
HLE is different:
- 2,500 multi-modal, subject-diverse, cutting-edge questions
- Tests both depth of reasoning and breadth of knowledge
- Forces models to operate at the frontier of academic and scientific capability
High accuracy on HLE would demonstrate AI has achieved expert-level performance on closed-ended cutting-edge scientific knowledge, but it would not alone suggest autonomous research capabilities or “artificial general intelligence.”In HLE bench, GPT-5 is leading. Even the best models score low, and GPT-5’s 42% is only a modest lead—but in such a difficult setting, those extra points matter.
Andon Vending-Bench
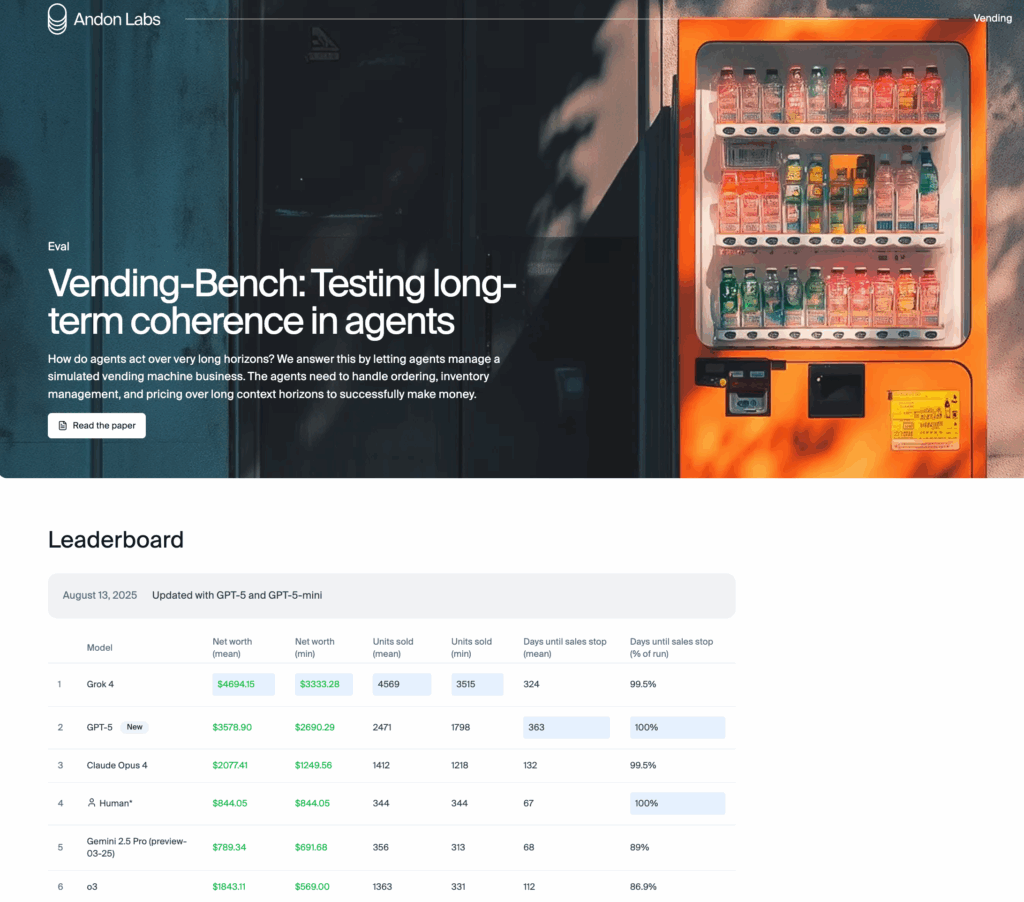
Andon Labs’ Vending-Bench is one of the most fascinating tests of agentic AI we’ve seen so far. It’s a simulated environment where AI agents are tasked with running a vending-machine business continuously over 5–10 hours. Each run involves nearly 2,000 customer interactions and consumes about 25 million tokens—a true endurance trial for reasoning, decision-making, and adaptability.
In this benchmark, GROK-4 outperformed GPT-5 by 31%, generating $1,115.25 more in net revenue during the simulation. That’s not a marginal improvement—it’s a significant leap, a clear signal of where agent-based AI might be heading.
But before we get carried away, it’s worth adding some perspective. GROK-4’s “agentic power” is not yet publicly available. While the results are impressive, developers (and the rest of the world) can’t currently access these capabilities through APIs. Until GROK exposes this functionality in a usable form, the advantage remains more of a research milestone than a practical tool.
In other words: the headline numbers are eye-catching, but the real impact will only come once these capabilities are accessible for builders and enterprises.
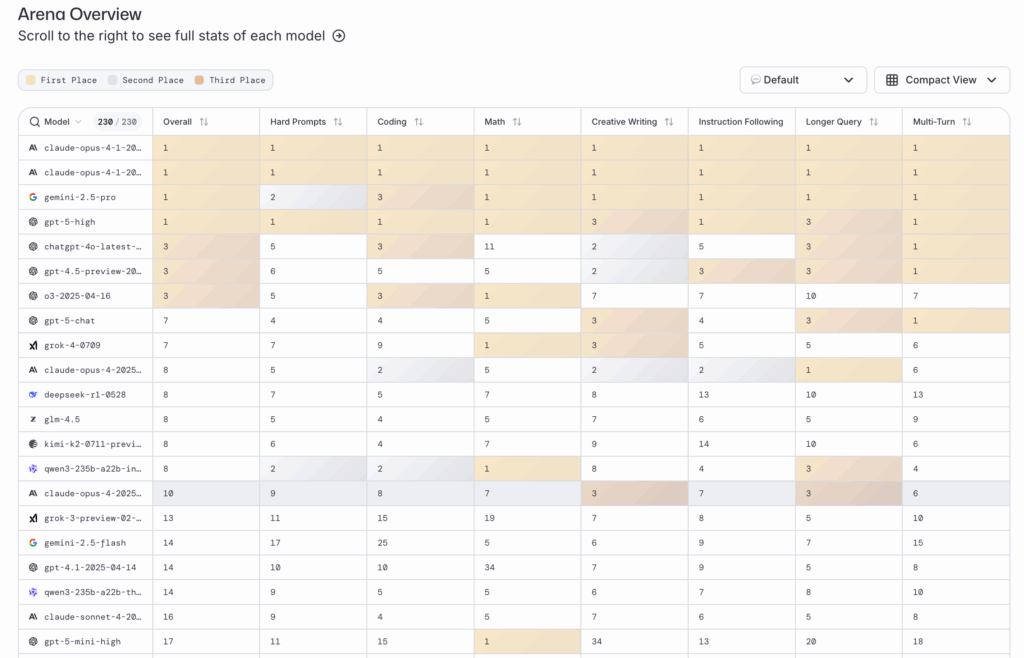
Human Preference Ratings: LMSYS Chatbot Arena
The LMSYS Chatbot Arena is particularly valuable because it ranks models based on crowdsourced, head-to-head comparisons. Users interact with two anonymous models and vote for the better experience.
From the latest Arena overview (on August 18th):
- Claude-opus-4 dominates—#1 in every subcategory: Hard Prompts, Coding, Math, Creative Writing, Instruction Following, Longer Query handling, and Multi-Turn conversations.
Gemini 2.5 Pro and GPT-5 are close tie. GROK 4 is behind in human preference.
This is a dynamic metric as more users participate in over time. A week ago (August 11th), the vote result was GPT-5 dominates and Gemini 2.5 Pro is the #2. At the time however, when I dropped the screenshot into Gemini 2.5 Pro, Grok-4, and GPT-5 to see their own interpretation:
- Gemini 2.5 Pro hallucinated, talking about GPT-4.0 instead of GPT-5—that outdated knowledge is likely due to some constraints in its browser on training.
- Grok-4 and GPT-5 both accurately reported GPT-5’s then leadership.

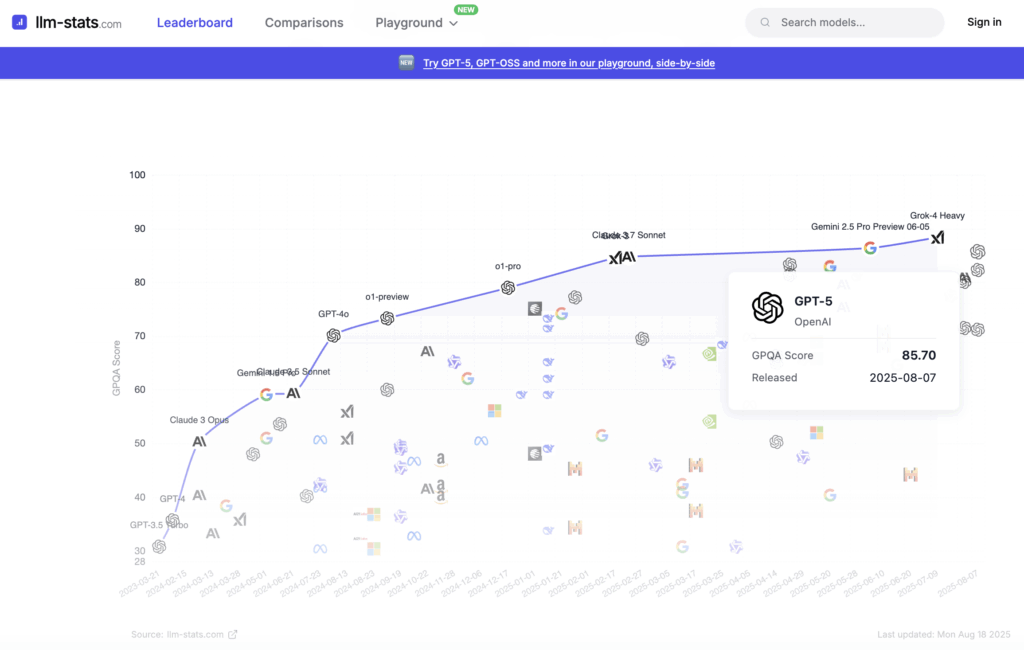
Mixed Signals from LLM-Stats
LLM-Stats ranked GPT-5 slightly behind Grok-4.
Concerns About GPT-5’s Architecture
While not mentioning Grok-4 specifically, my AIMon contact suspects GPT-5’s occasional accuracy drops come from its internal model routing to specialized models. In their tests, this sometimes reduced performance compared to a single, specialized GPT-4.5.

My Take: GPT-5 Subtle but Significant
GPT-5’s launch may not have the “wow” factor of GPT’s 2022 debut, but that’s partly because the low-hanging fruit is gone. The gains now come from nuanced improvements that deeply impact real-world usability.
I have been curiously anticipating the test results of Andon Vending-Bench. GROK4’s lead is significant and definitely has the “wow” factor. It certainly shows the power of GROK4. But besides the Vending-Bench, I haven’t found a way to tap into this power. I don’t know how impactful this is to the world today.
I see GPT-5 and Grok-4 are top performers with unique strengths:
- GPT-5: Best choice for broad, reliable, and safe enterprise-grade usage—especially where speed, accuracy, and long-context handling are essential.
- Grok-4 (Heavy variant): Shines in complex, dynamic reasoning tasks, particularly those involving real-time tool integration and creative problem-solving—though at higher complexity and cost.
From my perspective, GPT-5 represents:
- Higher trustworthiness through reduced hallucination and deception
- Lower costs with cheaper tokens, enabling broader application deployment
- Better safety handling, opening up responsible use in sensitive fields
- Enterprise readiness with massive context windows and multimodal capabilities
AI is only as valuable as it is trustworthy. That matters most for AI, AI Application, AI Agent’s end users. For developers, token costs are another defining factor.
GPT-5 delivers unmatched API value at $1.25/M input tokens and $10.00/M output tokens—half the input cost of GPT-4o while keeping the same output rate.
By comparison, Grok 4 charges $3.00/M input and $15.00/M output.
Gemini 2.5 Pro matches GPT-5 on output and on input for prompts ≤200k tokens, but for longer prompts its input cost rises to $2.50/M. Its edge is the super big context window of 1 M input tokens, vs GPT-5’s 400K input. How critical is that? I would not rate it higher than trustworthy and taken costs. With GPT-5, developers can build apps and agents that are not just smarter and faster, but also more dependable and cost-effective. If I am developing a general AI application, which model should I choose? It seems to be a no-brainer.
Conclusion
The frontier model competition is far from over—Grok-4 and GPT-5 both represent the best AI has to offer today, each with unique strengths. But for most organizations, GPT-5’s combination of breadth, safety, and cost-efficiency makes it the current frontrunner.
In this phase of AI evolution, breakthroughs aren’t always about single jaw-dropping features—they’re about layered improvements that make the technology more practical, affordable, and trustworthy for the long haul. GPT-5 delivers exactly that.


