
I’ve been a happy user of GROK for some time, and Wednesday’s GROK 4 announcement left me both amazed and a bit let down. As Elon Musk put it during the live stream: “With respect to academic questions, Grok 4 is better than PhD level in every subject, no exceptions.”
That’s insane, and the performance backs it up!
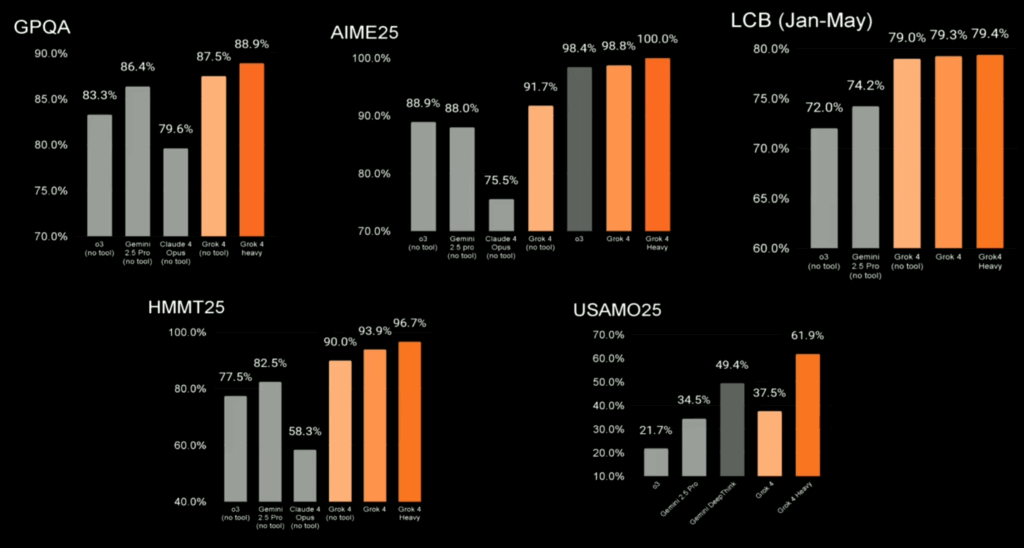
Superior Benchmark Metrics
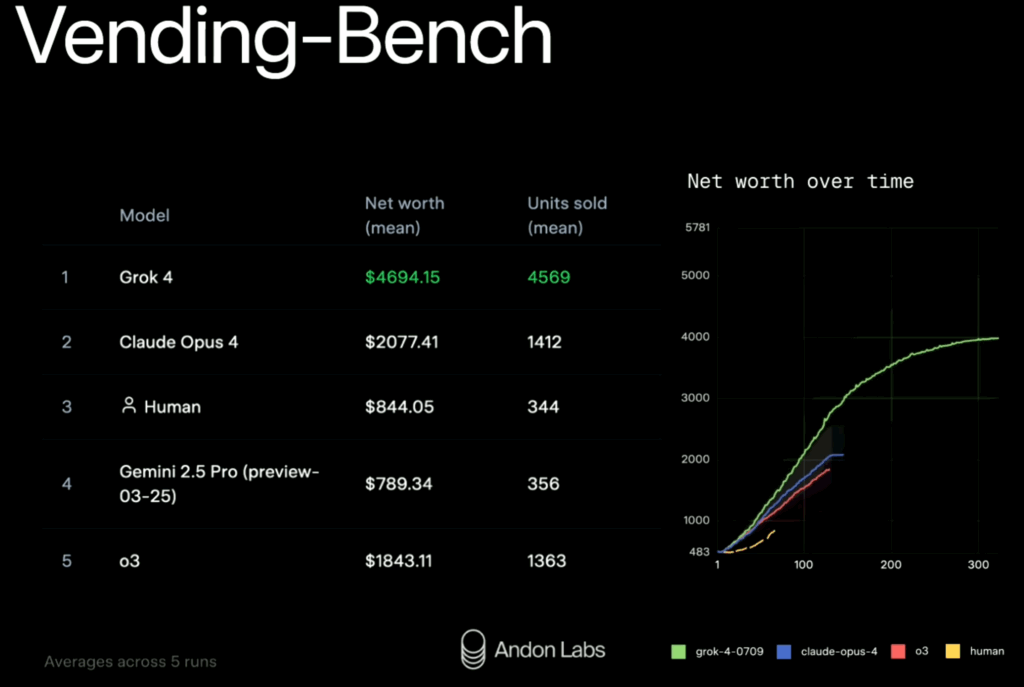
Beyond excelling in academics, Grok 4 shines in practical, long horizon tasks too. It topped Andon Labs’ Vending-Bench, a simulated environment testing AI agents’ ability to run a vending-machine business over 5-10 hours, with ~2,000 interactions and ~25 million tokens per run. Grok 4 outperformed others with a net worth of $4094.15 and 4569 units sold, showing the steepest growth curve—more than double the runner-up, Claude Opus 4.
What GROK 4 Offers Developers
For developers, GROK 4 brings some long-awaited exciting updates. The token caching capability is finally supported, reducing costs to $0.75 per 1 million cached input tokens (versus $3.00 standard). Additionally, GROK 4 introduces advanced tool calling, enabling seamless integration with external tools and services.
As someone passionate about AI agents, I often assess LLMs through the lens of multi-agent system support. Multi-agents architecture, if designed well, allows system scale with complexity and specialization. In the Vending-Bench test, Grok 4 operated as a single-agent system. There’s no indication it used subagents, role delegation, or any hierarchical reasoning. In short, this bench mark tested GROK 4 as a super agent, but not a multi-agent system.
The Missing Piece: Interleaved Thinking
GROK 4 supports multi-agents. But one crucial feature I look for is interleaved thinking, where a model thinks between tool calls and make more sophisticated reasoning after receiving tool results. It’s a capability to alternates between internal reasoning and external actions (like tool use) in a single session. It seems that GROK 4 doesn’t support it. Among today’s top models, only a few provide native support:
- Google Gemini API: Gemini 2.5 Pro and 2.5 Flash have “thinking models” with dynamic thinking (adjustable via a thinkingBudget). They can interleave tool call results and the next tool calls fluidly in a single turn. The Gemini API allows you to request thought summaries. These provide synthesized versions of the models internal reasoning process, giving developers visibility into how the model is interpreting tool results and making decisions.
- Anthropic Claude API: Claude Opus 4, Sonnet 4, and Sonnet 3.7 support “extended thinking” with internal reasoning blocks and interleaved thinking with tools, chaining multiple calls with reasoning steps in between, and making more nuanced decisions based on intermediate results.
- OpenAI’s Assistants API: Mimics interleaved thinking with multi-step tool use, memory, and function calls, though the ChatGPT API itself requires agent frameworks for this behavior (not native support).
Unfortunately, there’s no definitive evidence that the Grok 4 API supports interleaved thinking. I cannot find anything about it in xAI’s documentation as of July 10, 2025.
Elon Musk noted during the live stream, “At times, it may lack common sense, and it has not yet invented new technologies or discovered new physics, but that is just a matter of time.” While this hints at future potential, for developers like me, interleaved thinking and agentic capabilities remain a critical missing piece today.
#grok4 #ai #AiAgent #vending-bench #gemini #claude #chatGpt #LLM


